1 论文的核心工作
- 引入 WebWalkerQA,用于评估 LLMs 网络遍历能力的基准。评估 LLMs 遍历网站子页面以系统提取高质量数据的能力。
- 提出了 WebWalker,多智能体框架,通过探索-评价范式模拟类似人类的网络导航。
2 现代网络搜索的局限性
- Google 或 Bing,执行的是横向查询搜索,无法有效追踪嵌入在网站中的深层内容。
- 以往关于网页的研究主要关注处理基于动作的请求,但这些动作面临着信息过噪和输入过长等挑战,由于长上下文理解的限制,这会显著影响性能。
- 无法捕捉现实场景的复杂性,其中相关信息深埋于网页之中,需要多层次的互动才能获取
3 WebWalkerQA数据生成、标注策略
这个对我来说不是重点,可以参考原文了解。
4 WebWalker
WebWalker是一个多智能体框架,旨在通过垂直探索模拟类似人类的网页导航。
该框架由一个探索智能体和一个评价智能体组成。
鉴于推理能力对于有效导航和交互网页的必要性,探索者智能体基于 ReAct 框架构建,采用思考-行动-观察范式。
评论者智能体负责维护记忆并根据探索者智能体的探索结果生成响应。
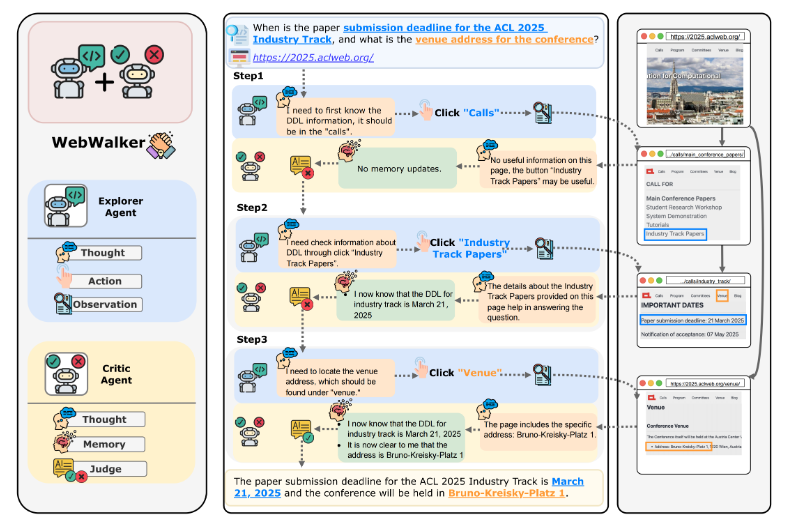
探索智能体会通过点击操作探索子页面,并会根据页面信息获取观察结果,然后基于既定策略采取行动。观察结果包含当前页面的信息以及子链接列表,探索智能体会在子链接列表中决策出一个链接继续深入探索。直到评价智能体决定回答用户问题或者达到最大步数。
评价智能体的评价时机在探索智能体每次获取观察结果之后,它会决定探索智能体是否继续深入探索。
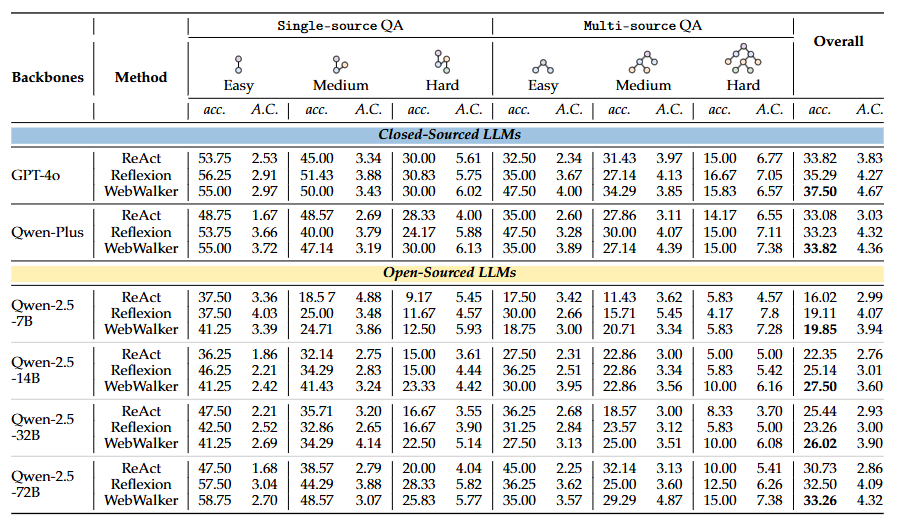
5 结果